ADVANCED TOPIC
Data Category (Low Level Data Object)
A logical unit of related data as defined by the business.
Data Categories are the building blocks used by Entities to access all of your business data.
You do not need to understand Data Categories to use DSF, however it may help you in Organizing your data.
As you may know, an RDBMS consists of tables and tables hold data. There can be relationships between tables (whether constrained or implied).
The following examples will utilize the sample database provided by Microsoft called: AdventureWorks.
The AdventureWorks database is an imaginary Manufacturing company.
The Entity Relationship Diagram (ERD) displays the table relationships for this database.

On the ERD, Microsoft was kind enough to break down the data into Schemas. A Schema is nothing more than a way to categorize common data tables into a group within an RDBMS. Schemas are not really important in understanding a Data Category since it is not a database requirement to organize tables with schemas and many databases don’t even have them.
ERDs can be very complex and sometimes hard to see how the table relationships are structured. DSF displays table relationships in a Hierarchical Treeview that most people are familiar with. It works the same way as the File Explorer in Windows.
We are using the Customer table from the ERD as the example. The word Sales separated by the dot then the word Customer (Sales.Customer), simply indicates that the Customer table is in the Sales Schema.
It could have just as easily just been a table named Customer with no Schema.
The ERD shows that the Customer table contains 7 fields.
| Customer |
| AccountNumber |
| CustomerID |
| ModifiedDate |
| PersonID |
| StoreID |
| TerritoryID |
| rowguid |
However when looking at the Hierarchical Treeview below notice 3 sub-folders. Person, SalesTerritory and Store.
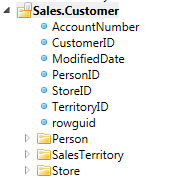
This is because there is a known relationship linking the Sales.Customer table to those folders. If we expand them we see this:
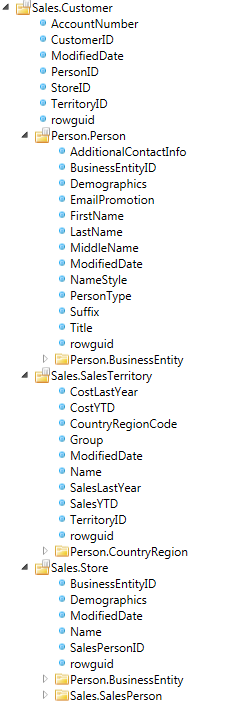
We haven't expanded every folder. However, if we had, the list of every field, in every folder and every folder's sub-folder in the treeview is a considered a single Data Category.
A domain of information or a logical unit of related data as defined by the business.
In this example we will call the entire treeview list the “Clients” Data Category. Let’s imagine that this is one of your core business elements. We just gave a Business name to the entire group of fields. Even though the first table in the list of tables is Sales.Customer, you as the business expert refer to sales customers as Clients.
We can change the name to something more meaningful.
In the treeview you cannot see what fields link the relationships between the folders like you can in the ERD diagram using lines between the tables. Table relationships in the RDBMS are immaterial to the report writer when sourcing data.
We want intelligent and easy access to the data in business terms NOT database terms.
The end-user using DSF does NOT need to know the RDBMS data table relationships to build a report.
The DSF user can just select the fields from the list of business categories they already understand. We list ALL fields available to put on a report related to Clients. The report writer should not care where they come from in the database.
In describing the Data Category and treeview example, we started referring to the tables in the RDBMS as folders. This is VERY important in understanding Data Categories. The folders you see in the treeview are NOT table references at all, as shown on the ERD. They refer to other named Data Categories that you can name yourself. Just like we did above with the top folder in the list “Sales.Customer” that we renamed to “Clients”. Since Clients is the name you know it by in your business.
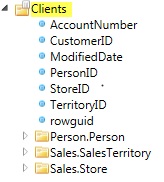
Each sub-folder is a Data Category. (Person.Person, Sales.SaleTerritory and Sales.Store) The sub-folder Data Categories are considered Reference Data Categories. The top most Data Category that we are now calling Clients is considered a Master Data Category. ALL databases have at least one concept of a Master Data Category which are the main business concepts or purposes of the database.
Most enterprise level databases have less than 20 Master Data Categories but could have hundreds or thousands of Reference Data Categories. Not something to worry about yet, but all Reference Data Categories can be used as Master Data Categories within their own context of data.
Looking at the AdventureWorks ERD above, we can quickly see that there is at least 5 Master Data Categories. Can you name them?
We know there are at least 5 because Microsoft has broken the AdventureWorks database into Schemas for us. They have grouped the data into “logical units of related data”. Straight from the pure definition of a Data Category above.
DSF Allows you to organize the fields and create groups using any names that are familiar to your business the same way you do file folders in windows explorer.
When your database is discovered by DSF the default field names and sub-folders are just best guesses based on the table names in your database. Like you can see above, the treeview names closely resemble each other. This is temporary. It’s only to give you a quick starting point. You can organize the fields and create groups using any names that are familiar to your business the same way you do file folders in windows explorer.
Just like we did with renaming Sales.Customer to Clients above. Any field within the same context of the Master Data Category can be moved into any group you desire. You can even have the same field in different groups with different names for convenient access and clarity.
In the picture below we have changed the names of the Data Categories to make it easier for the report writer to find the data they are looking for in the business terms they would understand.
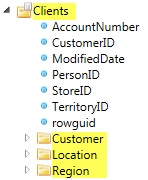
Person.Person is now Customer, Sales.SalesTerritory is Region and Sales.Store is now Location.
You can name and group folders and fields anyway you like, this is just one example to show you the flexibility of DSF. Fields can be copied into any group of your choosing. They DO NOT have to follow the structure of the database.
The power of DSF allows you to organize your data elements in any way you feel will be the easiest way for you and your colleagues to understand them in business terms. It does not matter how the fields are named or where they are located in your database.
You can categorize your data fields anyway you want, the same way you categorize your spreadsheets or document files in windows.
Wouldn't it be much easier when building a report to just pick whatever data fields you need from a long list of fields available in the Clients Data Category by yourself? Organized in a way of your choosing?
A DBA reading this may say “I can create a View (SQL Query) that will just return all of the fields then the end-user can pick and choose what they want. What’s the issue?”
Something important to remember. The example here is using the simple AdventureWorks database where everything is perfect and you can easily understand the field and table names. In your database the table name that holds the CountryRegionCode could be called Location and the field name could be CC. So the DBA has to do the translation work for you. Also, the Data Category above that started with the Sales.Customer table, that we renamed to Clients, only shows a few fields. So yes, the DBA is right, a single View can handle a few fields.
More importantly, in a real enterprise database, Data Categories can have tens of thousands of fields in the treeview. Is the DBA really going to write one query that returns thousands of fields with thousands of records every time it’s run, just in case you might need one of the fields sometime in the future? The answer is No.
Envision a giant SQL Query, which the DBA will never write for you, that starts with a top most purpose, “Clients”. It then traverses down through every possible field that could ever be reached as it relates to Clients. Then the next and then next until it reaches a point where there is no more data related to Clients. It doesn't stop until all possible references are exhausted. That’s a lot of data fields!
Why would you want to transfer hundreds of fields from the database server to the client workstation, for possibly thousands of records, when the only data the user needs today is 3 fields?
Is the DBA really going to write you a View to return every possible field? No. They won't.
Here's why; Performance, network traffic, server load and memory.
Seems like a gross waste of time and resources if you ask me. That’s like going to the grocery store, paying for, bagging and bringing back home hundreds of items and then throwing away all but the 3 you need!
Will the DBA attempt to write hundreds of views with different fields to fit most of your reporting needs? Will the developers create some Ad-hoc reporting tool that gives you only limited data fields? This is the current reporting model. Again, with thousands of data fields there are billions of permutations that the user could want. IT can never cover them all.
Just like you would not go to the store and buy ALL of the meat they sell just to come home and make a hotdog. Why bring home liver when you know you will never eat liver. It’s a waste of time and resources.
To alleviate the waste, DSF simply lists everything available for purchase at the store. It displays the inventory list of what the grocery store carries on its shelves. You don’t need to actually go to the store until after you have picked what you want that the store sells and add it to your list. Then you go to the store and only come back with what was on your list. You can even change your list whenever you want. It’s your list.
The idea of a Data Category abstracts all of the technical details of the nested table reference complexities and presents it to the user in Business Terms. The Data Category is NOT a query like the IT crew needs to write. It simply presents “What” fields are available in the “Context” of the Data Category's name.
It just shows you ALL fields available related to the business term “Clients”. Only after you have picked from your long list of possibilities do you actually want to go to the database to get your data.
Example:
Think of it as a map of roads starting at your house. A road from your house somehow links to the next town and then roads from that town somehow link to the next town after that until you reach all dead ends.
Each town is a Data Category and each house is a field. Each town could have their own series of maps to get to each house (a Data Category). If the town is already mapped you can just reuse their map when you get there. No need to re-map it again unless you want to.
Maybe they mapped it using surveyor Block and Lot Numbers and you want to change them to their postal house numbers or family names. You could use their map and change the names to better align with your business.
If there is a river with no bridge (relationship) to the next town then you cannot get to it. The same way you cannot get to data in a Data Category unless there is a relationship between where you are and the next Data Category.
Furthermore, you don’t need every road mapped to reap benefits from the map. You can always map more as the need arises. Same is true with Data Categories. You don’t need thousands of fields day one.
DSF is different in the fact that it uses smaller Data Categories as building blocks to construct large ones but creates separate unique context for each one as it is reused.
Data Categories in the database have a specific categorical purpose. There are Master Data Categories and Reference Data Categories. Reference Data Categories are smaller in size and are the blocks to construct larger Master Data Categories.
It’s important to know that once a Data Category is “mapped” meaning documented in DSF, it can be reused over and over again with different Entities.
Summing it up
Data Categories:
- Can be named anything you wish.
- Are NOT SQL Queries.
- Are only a structure of what data elements are available to the user within a specific business context.
- Can contain thousands of data elements.
- Are re-usable to build bigger more complex Data Categories.
- Only need to be defined once.
- Can be used as a Master or Reference Data Category determined by point of entry.
- Do NOT return data.
- Can be a complex nest of linked Data Category relationships or as simple as one field.
- Have a specific categorical purpose.
- Do not need to be complete to reap reporting benefits.
- Can be expanded and modified as the database evolves.
- Are finite in contextual number within any RDBMS.
- Are defined by the business owner or software vendor and strictly tied to the RDBMS structure based on the products general purpose.
- Cannot be jumped contextually unless they are linked.